
今天我们敲击键盘输入的 A、B、C,对人来说是字母,但对计算机来说,它们只是 0 和 1。
那么,计算机是怎么理解 A 代表大写字母 A,而不是随意的数字呢?
答案就是 —— ASCII 码。
ASCII
在 1960 年代,美国的电传打字机(Teletype,TTY)厂商都有自己的“字符集”,互不兼容,通信很麻烦。

每个字母都需要转换为电信号(0/1脉冲)传输,当时电报系统通常使用 5 位(Baudot code)、6 位(Fielddata code)表示字符。
美国标准协议(ASA,后来改名为 ANSI)在 1963 年发布了 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)。

ASCII是第一套被广泛采用的基于英文的字符编码标准,使用 7 位二进制数(bit)来表示字符,最多能表示 2^7 = 128 个符号。
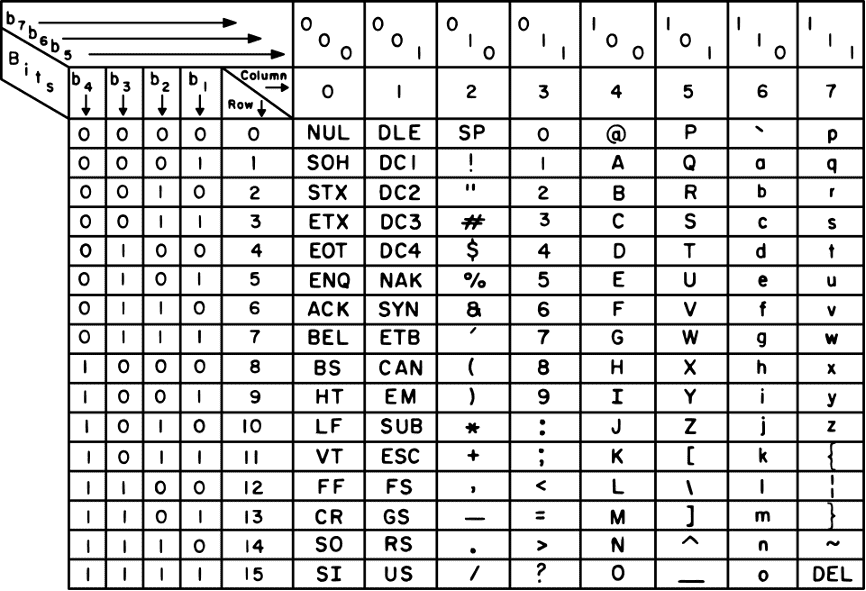
图片中的 ASCII 表,纵轴和横轴组合成 7 位二进制。
字符示例
例如 5 的ASCII 码:
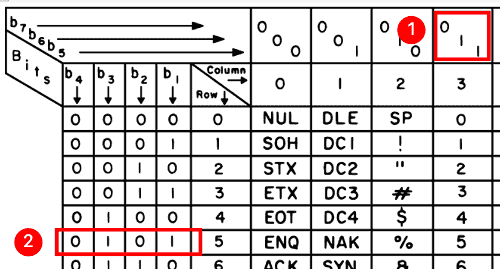
先看上面的b7、b6、b5,对应的数值为 011;
再看左侧的b4、b3、b2、b1,对应的数值为 0101。
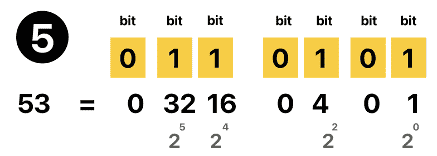
所以 5 的 ASCII 码二进制表示为 011 0101,十进制表示为 53。
ASCII和计算机的关系
1、计算机存储单位的由来
计算机的 CPU、内存芯片、总线设计决定了“最小一次能读/写多少位”。
早期有 6 位机器(DEC PDP-6)、9 位机器(CDC 6600),在存储单位上并不统一。
后来逐渐统一为 8 位作为最小存储单位。
原因:
1、ASCII 完全可以放进 8 位,并利用剩下的1位做校验/扩展;
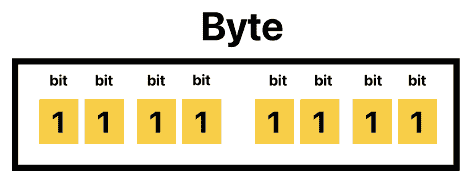
2、8 位与二进制十六进制自然对齐(1 Byte = 8 bit = 2 个十六进制数)。
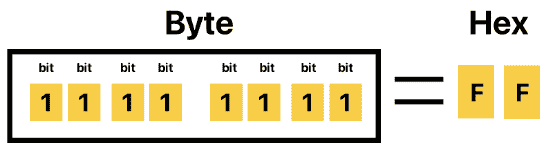
3、内存对齐效率高(字节寻址比“位寻址”简单得多)。
于是,硬件厂商逐渐把 8 bit 作为最小寻址单位,称为 Byte(字节)。
ASCII 虽然只有 7 位(bit),这也就意味着存储的时候,通常会将最高位(第 8 位)填 0。
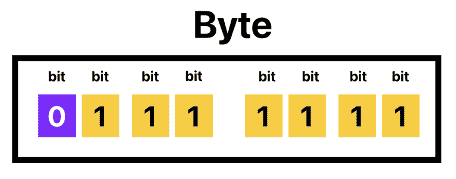
注:bit 是计算机最小的存储单位,只能存储 0 或 1,通常使用小写字母 b 表示。1 Byte = 8 bit,也就是一个 ASCII 字符,通常使用大写字母 B 表示。
2、ASCII的历史时间线
1963:ASCII 初版发布(7位,128个字符)。
1968:美国总统林登·约翰逊签署行政命令,要求所有美国联邦政府计算机必须支持 ASCII,这推动了 ASCII 的普及。

1970s:IBM、DEC 等大厂采用 ASCII,ASCII 成为计算机与终端通信的通用语言。
1981:IBM PC(个人电脑)发布,采用扩展 ASCII(8 位,256 个字符),彻底把 ASCII 推向全球。
扩展ASCII
在 1980 年代,计算机开始走向国际化, ASCII只支持英文,欧洲国家、科学符号、图像字符都无法使用。
ASCII只使用 7 位二进制数字符,第 8 位默认填 0,所以各个厂商就把最高位从 0 改成 1,定义额外的字符,这就是扩展ASCII。
扩展ASCII使用 8 位二进制数来表示字符,最多能表示 2^8 = 256 个符号。
在ASCII的基础(0-127,和ASCII保持一致)上,增加了 128 个额外字符:
1、各种语言的重音符号字母(é, ñ, ü);
2、线条符号、特殊图形;
3、一些数学符号。
因厂商不同所以扩展标准不同:
1、IBM PC 定义了带有笑脸、框线、希腊字母等符号。
2、ISO 制定了 ISO 8859 系列(如 ISO-8859-1 “Latin-1”,包含西欧字符 é、ñ 等)。
例如,é 可能 = 233 (0xE9);
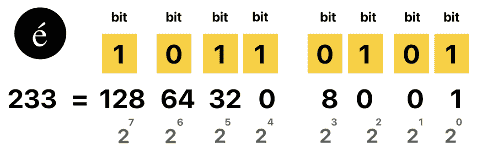
ç 可能 = 231 (0xE7)。
3、Macintosh有MacRoman 编码。
4、Windows有Windows-1252编码;
所以,扩展ASCII并不是一个统一的标准,在 8 位字节中,前 128 位兼容ASCII,后 128 位各自扩展各自厂商的编码。
Unicode编码
ASCII 是一切的开端,但它只有 128 个字符,只能覆盖英语世界。随着全球化的不断发展,扩展ASCII出现了“乱码问题”:
1、在法语电脑上,128–255 是 é、à 等。
2、在俄语电脑上,128–255 是 кириллица(西里尔字母)。
3、在 PC 上,128–255 可能是框线符号。
在计算机上相同的一个字节值,显示的字符完全不同,这是因为各厂商扩展 ASCII 各搞各的,互相不兼容。
为了解决这个问题,Unicode联盟成立于1991年,Unicode 1.0 规范发布在 1991–1992 年。它几乎囊括了全世界的文字符号(现在甚至超过 100 万字符), 定义了全球统一的字符集,每个字符分配唯一编码,ASCII 范围(0–127)完全兼容,保证历史兼容性。包括 emoji、中文、阿拉伯文等等。

例如,😊 = U+1F60A,U+表示这是一个Unicode code point(码点),1F60A 是一个十六进制数,换算成十进制就是 128522。
在UTF-8中占4字节:

注:UTF-8是Unicode的一种实现方式,还有UTF-16、UTF-32。
总结
ASCII 是计算机的第一套字符标准,让机器能理解 A-Z、0-9、标点和控制符。
ASCII使用 7 位二进制,能表示 128 个字符;扩展ASCII 使用 8 位二进制,最多表示 256 个字符,不同国家/厂商定义不一样;Unicode统一了扩展ASCII互不兼容的问题。
ASCII 奠定了现代编码的基础,直到今天依然在 Unicode 里占据重要位置。
所以,下次在电脑中输入 A 的时候,可以想一想 —— 在计算机眼里,它其实只是 0100 0001。
扩展图文
标准ASCII码
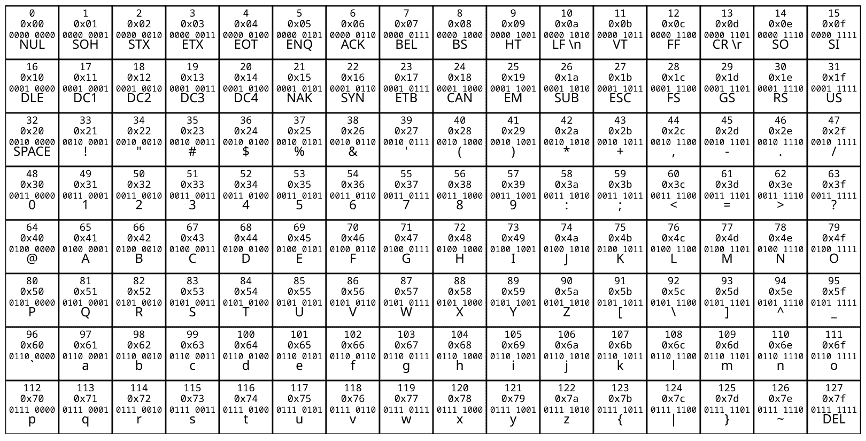
扩展ASCII码
参考文章
1、ASCII – 维基百科:https://en.wikipedia.org/wiki/ASCII
2、林登·约翰逊:https://zh.wikipedia.org/zh-cn/%E6%9E%97%E7%99%BB%C2%B7%E7%BA%A6%E7%BF%B0%E9%80%8A
3、Teleprinter:https://en.wikipedia.org/wiki/Teleprinter
4、Unicode:https://zh.wikipedia.org/zh-cn/%E7%BB%9F%E4%B8%80%E7%A0%81


