
In-place 排序(原地排序)是一种排序算法,它直接在原数据结构上进行操作,而不需要额外的大量内存空间来存储中间数据或排序结果。原地排序的主要特点是空间复杂度较低,通常是 O(1) ,即只使用了少量的额外空间。
In-place 排序的特点
1、低空间复杂度:原地排序仅使用少量辅助变量或指针来操作数据,不需要额外的数组或容器。
2、原数据修改:排序直接对原始数据进行修改,排序结果会覆盖原来的数据。
3、高效的内存利用:在资源有限的情况下(如嵌入式系统),原地排序非常重要。
常见的 In-place 排序算法
以下是一些典型的 In-place 排序算法:
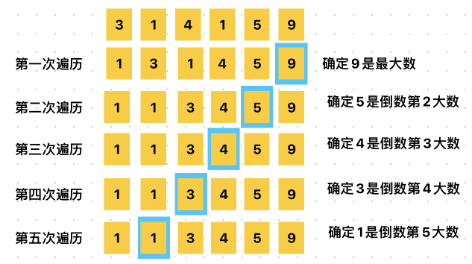
1、冒泡排序(Bubble Sort)
每次比较相邻的两个元素,并根据大小交换它们的位置。
空间复杂度: O(1)
时间复杂度: O(n2)
var array = [3, 1, 4, 1, 5, 9]
for i in 0..<array.count {
for j in 0..<array.count - i - 1 {
if array[j] > array[j + 1] {
array.swapAt(j, j + 1)
}
}
}
print(array) // [1, 1, 3, 4, 5, 9]
2、插入排序(Insertion Sort)
逐步将元素插入到已排序的部分。
空间复杂度: O(1)
时间复杂度: O(n2)
var array = [3, 1, 4, 1, 5, 9]
for i in 1..<array.count {
var j = i
while j > 0 && array[j] < array[j - 1] {
array.swapAt(j, j - 1)
j -= 1
}
}
print(array) // [1, 1, 3, 4, 5, 9]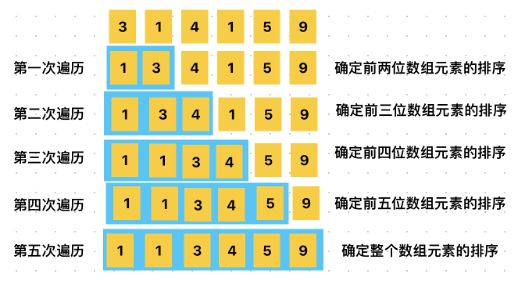
3、选择排序(Selection Sort)
每次找到剩余未排序部分的最小值或最大值,并将其放到正确位置。
空间复杂度: O(1)
时间复杂度: O(n2)
var array = [3, 1, 4, 1, 5, 9]
for i in 0..<array.count {
var minIndex = i
for j in i+1..<array.count {
if array[j] < array[minIndex] {
minIndex = j
}
}
array.swapAt(i, minIndex)
}
print(array) // [1, 1, 3, 4, 5, 9]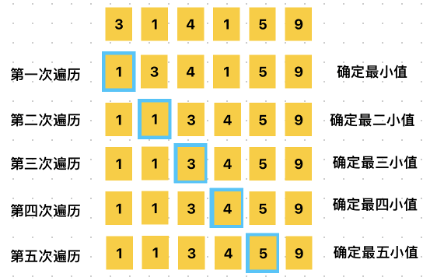
4、快速排序(Quick Sort)
使用分治法,通过选择一个基准值(pivot),将数组划分为两部分,然后递归排序两部分。
原地版本的快速排序对数组进行就地划分。
空间复杂度: O(log n) (递归栈)
时间复杂度: O(n log n)
func quickSort(_ array: inout [Int], low: Int, high: Int) {
if low < high {
let pivot = partition(&array, low: low, high: high)
quickSort(&array, low: low, high: pivot - 1)
quickSort(&array, low: pivot + 1, high: high)
}
}
func partition(_ array: inout [Int], low: Int, high: Int) -> Int {
let pivot = array[high]
var i = low
for j in low..<high {
if array[j] < pivot {
array.swapAt(i, j)
i += 1
}
}
array.swapAt(i, high)
return i
}
var array = [3, 1, 4, 1, 5, 9]
quickSort(&array, low: 0, high: array.count - 1)
print(array) // [1, 1, 3, 4, 5, 9]快速排序的核心思想
快速排序通过以下步骤完成排序:
1、选择一个基准点(Pivot):
通常选择数组的最后一个元素(或其他策略),作为基准值。
2、分区(Partition):
将数组划分成两部分:
左部分:所有小于基准值的元素。
右部分:所有大于等于基准值的元素。
此过程会确保基准值位于最终排序后的正确位置。
3、递归地排序两部分:
分别对左部分和右部分递归应用快速排序,直到每部分长度为 1 或 0(此时已经有序)。
快速排序代码分析
func quickSort(_ array: inout [Int], low: Int, high: Int) {
if low < high {
let pivot = partition(&array, low: low, high: high) // 分区操作,获取基准点的索引
quickSort(&array, low: low, high: pivot - 1) // 递归排序左部分
quickSort(&array, low: pivot + 1, high: high) // 递归排序右部分
}
}quickSort 是一个递归函数。
它通过调用 partition 函数将数组分成两部分。
分区后的左、右部分分别通过递归调用 quickSort 进行排序。
func partition(_ array: inout [Int], low: Int, high: Int) -> Int {
let pivot = array[high] // 基准点是最后一个元素
var i = low // i 指向分区的分界点
for j in low..<high {
if array[j] < pivot { // 如果当前元素小于基准值
array.swapAt(i, j) // 交换小元素到分界点位置
i += 1 // 分界点右移
}
}
array.swapAt(i, high) // 将基准点放到分界点位置
return i // 返回基准点的最终位置
}核心作用是将数组重新排列,使得基准值的左侧全是比它小的元素,右侧全是比它大的元素。
返回值是基准值的索引,表示其最终的排序位置。
快速排序的意义
1、高效:
平均时间复杂度为 O(n log n) 。
比如对于 100 万个元素的数组,分治法能迅速缩减规模。
2、灵活:
可以适用于各种规模的数组。
3、原地排序:
快速排序无需额外的内存(空间复杂度为 O(\log n) )。
不足之处
最坏情况下(如数组本身有序)时间复杂度可能退化为 O(n2) 。
不稳定排序:相同元素的顺序可能会被打乱。
非 In-place 排序的例子
对比原地排序,有一些排序算法需要额外的空间。
1、归并排序(Merge Sort)
需要创建额外的数组来存储中间结果,因此不是原地排序。
空间复杂度: O(n)
时间复杂度: O(n log n)
func mergeSort(_ array: [Int]) -> [Int] {
guard array.count > 1 else { return array }
let mid = array.count / 2
let left = mergeSort(Array(array[..<mid]))
let right = mergeSort(Array(array[mid...]))
return merge(left, right)
}
func merge(_ left: [Int], _ right: [Int]) -> [Int] {
var result: [Int] = []
var i = 0, j = 0
while i < left.count && j < right.count {
if left[i] < right[j] {
result.append(left[i])
i += 1
} else {
result.append(right[j])
j += 1
}
}
result.append(contentsOf: left[i...])
result.append(contentsOf: right[j...])
return result
}
let array = [3, 1, 4, 1, 5, 9]
let sortedArray = mergeSort(array)
print(sortedArray) // [1, 1, 3, 4, 5, 9]总结
In-place 排序 是直接修改原数据的排序方法,通常占用更少的内存。
常见的 In-place 排序算法包括冒泡排序、插入排序、选择排序和快速排序。
非 In-place 排序(如归并排序)虽然占用更多内存,但在某些情况下可能更适合需要稳定排序或更复杂场景的需求。
选择排序算法时,应根据数据规模和系统资源的限制来决定使用 In-place 还是非 In-place 排序方法。


